How to use google spreadsheets to check for broken links
At work, I like to automate my tasks. If I find my self repeating one or more steps for a given task, the programmer in me snaps and I dedicate my efforts to avoiding that repetition.
One of the tasks I got at work is, given a list of URLs from our university’s internal search engine, find the links that are either broken or redirected to new links.

Usually, this is a very simple task. All I would have to do is click the link in the URL column and see if it’s working, redirecting, or not found. However, what if I get a list that’s more than 100 rows long? As a matter of fact, shortly afterwards someone on the team brought up an issue that our aggregate list of keywords needs to be checked for broken and redirected links as well. And that list is over 2000 rows long.
Google Apps Script: Overview
Enter Google App Script, google’s Gsuite scripting platform. Google App scripts allows you to create your own custom scripts/functions that interact with google’s Gsuite products like Google Docs, Sheets, Calendar etc.
In this case, I am using google’s script editor to write my own custom google sheet function (like =SUM()) to make http requests to a list of links from the spreadsheet and the function returns the status code returned from that request. What I like about this scripting feature is that it’s integrated into all spreadsheets and your code can be written in javascript.
Step 1: Create/Import spreadsheet in Google Sheets
The easy part. Create a new Google sheet and either import your list of links or add them manually in whichever columns you want.

Add a column that will check for the status of the links in the URL column. In my case that’s the Status Code column.
Step 2: Write a custom function in the Script Editor
This is the magical part. From the toolbar go to the Tools menu and click Script editor.

This will open a new page where you can write your custom function. The default function name is myFunction(). I will change this to a more descriptive name getStatusCode().
function getStatusCode(url){
var response = UrlFetchApp.fetch(url);
return response.getResponseCode();
}The purpose of this function is to take in a single URL and return the Http status code returned when connecting to that address. Therefore, I will pass the function a single parameter called url.
Next I create a variable called response and use the fetch method of the UrlFetchApp class to make a request to fetch the URL. This will return an Http response object. I then use the getResponseCode() method to get the response code from the Http headers.
The number code that indicates a good healthy link is 200. The famous 404 means page is not found/removed, and 3xx means a page redirect. There are many others that you can check out here.
Step 3: Test your function in the spreadsheet
Now you get to see your function in action. In the cell next to the first URL, type in =getStatusCode(a2) and hit enter to execute the function.
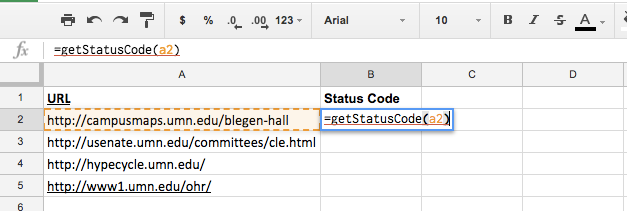
For testing purposes I picked 4 different links each of which I know has a different status code, the order of which are 200, 404, 503, and 301.
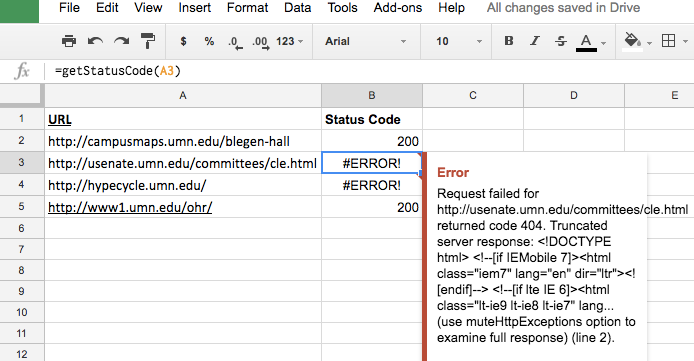
When I use the function to test the other links, I get unexpected values. The 404 and the 503 links returned the expected codes but the function threw an inconvenient #ERROR! that you have to hover on to read the code returned. This happens because the fetch() function returns only successful calls which are basically 2xx codes.
What about the last link? Wasn’t it supposed to return a 301?? Again we can blame this on the fetch() function since the server redirected it to the new page location that gave it a 200 code in the end which explains the value in the sheet cell.
Step 4: Back to the Coding Board
Now that we see the pitfalls in our code, we have to do some adjustments to catch those edge cases we tested. To begin with, we want to catch the errors, which in this case are the other Http error codes. We also want to stop fetch() from following redirects and to return the initial redirect code.
In order to do so, we need to pass in a second parameter to the fetch() method to tweak some of its properties.
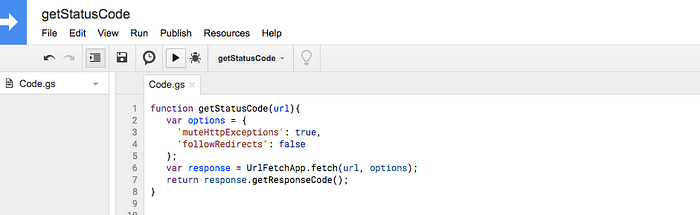
function getStatusCode(url){
var options = {
'muteHttpExceptions': true,
'followRedirects': false
}; var url_trimmed = url.trim(); var response = UrlFetchApp.fetch(url_trimmed, options);
return response.getResponseCode();
}
We create the second parameter, named options, as an object. The first property we’re changing is the ‘muteHttpExceptions’ to true. By doing this we stop the fetch() method from throwing an error that breaks our function flow. As you might have guessed, the default is false and that’s why we’re changing it to true.
The second property we’re changing is ‘followRedirects’. This is the property that tells the fetch() method whether to follow 3xx redirects to final destination or not. We set this to false so we don’t get fooled by the 200 we got before.
You may have noticed that we modified the url as well. As pointed out by Glenn Smith in the comments, URLs with leading or trailing spaces can cause errors. To account for that case, we use the .trim() method on the url string to remove any leading or trailing spaces.
Now that our options properties are set, we pass it to the fetch() method as a second parameter and save our code.
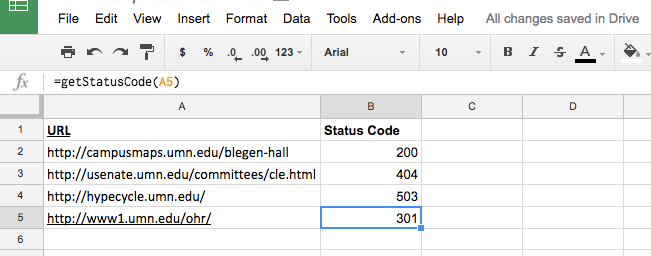
Now when you go back to the spreadsheet and test your function again, you should see that the function no longer returns that ugly #ERROR! message nor does it get fooled by a 301 redirect.
Step 5: Optimize Efficiency & Avoid Request Quotas
After 4 years since writing this script, Daniel Silver pointed out to me an interesting error that shows up:
Service invoked too many times for one day: urlfetchThis is Google telling us that our script has ran too many requests in one day and reached its allowed quota which is 20,000 requests/day or 100,000 requests/day depending on your account type.
To solve this issue, we can use a CacheService object which creates a cache (a local storage) tied to our script. Now I re-write my script as follows:
What’s different? First thing I did is initialize and retrieve a cache object on line 4. This cache is going to have any url/responseCode pairs we stored from previous runs. If it is the first time to run it, it will just be an empty object, which is fine.
On line 5, we search the cache for the given url to see if we requested it before and store it in result . If it is the first time the script sees this url, the result will be undefined and so the script will execute the code inside the if block, which is the same logic as before except for one little change.
cache.put(url_trimmed, responseCode, 21600)Instead of immediately returning the response code to the sheet, this line stores the response code with its corresponding url in the cache object we created earlier. The third parameter is a number representing the amount of time this value is going to last (in seconds). I am using the maximum expiration time here of 6 hours.
So how does this solve the problem? When you open the spreadsheet for the first time one day, it’s going to run all the requests from scratch for each url you define. However, for the subsequent 6 hours, no matter how many times you refresh the page or how many other users view it, the script will fetch the cached results instead of requesting them again and again, saving time and avoiding that quota limit. You can still add new urls to the sheet and they will fetch new requests initially, then results will be stored in the same cache.
And that’s it! You can use those few lines of simple javascript code to leverage Google’s App Scripts and run it on hundreds or thousands of URLs in a spreadsheet without having to click on each link manually.
There are many other methods and tricks you could use to customize this function but it all depends what information you’re looking for and what you want to do with it.
